

Nowhere To Hide
Your life so far has been a big data trail for someone else to mine.
Google took what was essentially crumbs of data left by millions (billions?) of people as they navigated around the internet, compiled and analyzed it into …
Your life so far has been a big data trail for someone else to mine.
Google took what was essentially crumbs of data left by millions (billions?) of people as they navigated around the internet, compiled and analyzed it into …
Despite bigger and bigger data, the world is a small place and it is full of people. Increasingly networked people. I like Clay Shirky’s thinking in Here Comes Everybody about new ways people online can gather and form loose communities …

It is no longer news that companies can (and must) look for competitive advantage and innovative, even disruptive, opportunities in their “big data”. We are flooded daily with press releases about new big data technology, much of it designed to …
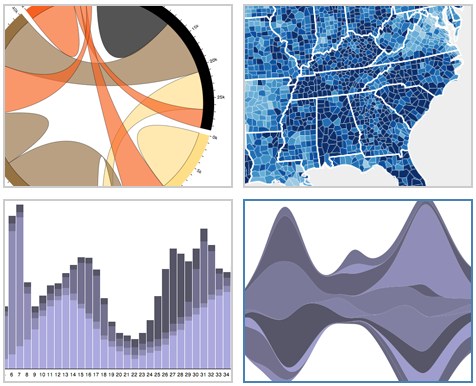
Check out this javascript library D3 for “Data Driven Documents” (D3 on Github). At first D3 seems to be just yet another way to add graphs and charts to web pages, but if you spend a few minutes …
If a Big Data set (or smaller data) is in the form of documents, then it’s difficult to store them in a traditional schema-defined row and column database. Sure, you can create large blob fields to hold large arbitrary chunks …

If you think of an HTML page as a structured “marked up” document, it’s basically a form of data. The structure, in this case represented by HTML tags like <a> and <div>, identifies various document elements which can be interpreted …