
Video: Why Facebook and the NSA love the graph database
(Excerpt from original post on the Taneja Group News Blog)
…(read the full post)…
…(read the full post)…
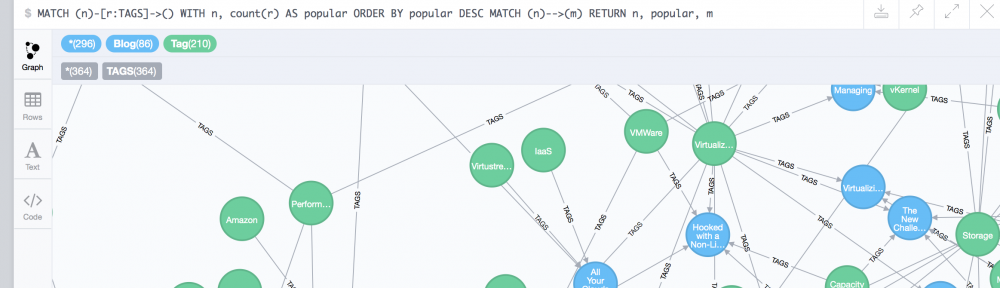
I’ve been playing again with Neo4j now that v3 is out. And hacking through some ruby scripts to load some interesting data I have laying around (e.g. the database for this website which I’m mainly modeling as “(posts)<-(tags); (posts:articles)<-(publisher)”).
For …
 Is there a benefit to understanding how your users, suppliers …
Is there a benefit to understanding how your users, suppliers …